
Researchers from HKU and Tencent have proposed a new paradigm for multimodal recommender systems -- theDiffMMThe aim is to increaseShort VideoRecommendation accuracy. The system achieves more accurate recommendations by creating a graph containing information about users and videos and utilizing graph diffusion and contrast learning techniques to better understand the relationship between users and videos.
DiffMM ' s model methodology consists of three main components: multi-mode map diffusion model, multi-mode map aggregation and cross-mode comparison enhancement. Among them, the multi-modular diffusion model uses a model to detect the probability of noise diffusion, aligning the user-matter synergetic signal with the multi-modular information and effectively addressing the negative effects of the multi-modular referral system. At the same time, the production and optimization of model sensory images has been achieved through the optimization of the diffusion of the probabilistic proliferation paradigm and model perception。
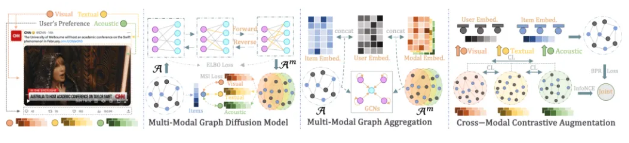
In terms of cross-modal contrast enhancement, DiffMM utilizes modality-aware contrast view and contrast enhancement methods to capture the consistency of user interaction patterns on different item modalities and improve recommender system performance.
Paper:https://arxiv.org/abs/2406.1178