About Openclaw memory, you just need to see this。
NO PAPERS, NO WORDS. AFTER READING THIS, YOU'LL KNOW MORE ABOUT AI THAN 901 TP3T。
I'll take itOpenClaw TAKE A LOOK AT HOW THE ENGINEERS ARE GIVING AI ONE STEP AT A TIME
From the roughest of options to the most forward line of thinking。
AI, WHY AMNESIA
LET'S FIND OUT THE BASIC QUESTION: WHAT IS AI'S BRAIN。
When you talk to ChatGPT, Claude, these AIs, you probably think it's like a human being, and you remember what you talk about。
Not really。
AI'S BRAIN IS NOT A HARD DRIVE, IT'S A DESK. THE SIZE OF THE DESK IS FIXED, AND EVERY WORD YOU SAY TO IT, AND EVERY WORD IT RETURNS, IS A PIECE OF PAPER ON THE TABLE. WHEN THE TABLE IS FULL, THE NEW PAPER WILL NOT BE RELEASED。
This desk, technically called the context window。
Now the big model, the table's not small, Claude's table probably opens up a whole Harry Potter. That sounds big. But the problem is that every word you talk about itself is on the table. The longer the conversation takes, the thicker the record of the dialogue on the table, the less room is left for real work。
EVEN WORSE, AI DOESN'T HAVE A DRAWER. HUMANS CAN PUT WHAT IS NOT NEEDED FOR THE TIME BEING IN THE DRAWER AND TURN IT OUT WHEN THEY NEED IT. BUT FOR AI, THERE IS NOTHING ON THE TABLE。
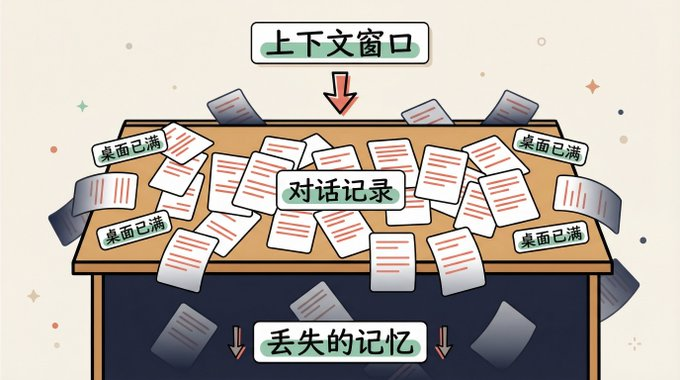
When the table is full, old things are pushed down and left empty。
IT'S NOT AI STUPID, IT'S STRUCTURAL CONSTRAINTS. JUST LIKE YOUR BROWSER, IT'S THIS BIG, ROLL DOWN AND IT'S INVISIBLE. THE DIFFERENCE IS, YOU CAN STILL TURN BACK, AI CAN'T. GET THE HELL OUT OF HERE, IT DOESN'T EXIST FOR IT。
What if the table's full? The most intuitive idea is to rub old paper, press it, and make room。
OpenClaw's first plan, that's all。
Option 1: Scroll old notes into paper
OpenClaw is an open-source AI programming assistant platform that you can interpret as an AI programmer management system。
It initially dealt with memory in a simple and brutal manner:
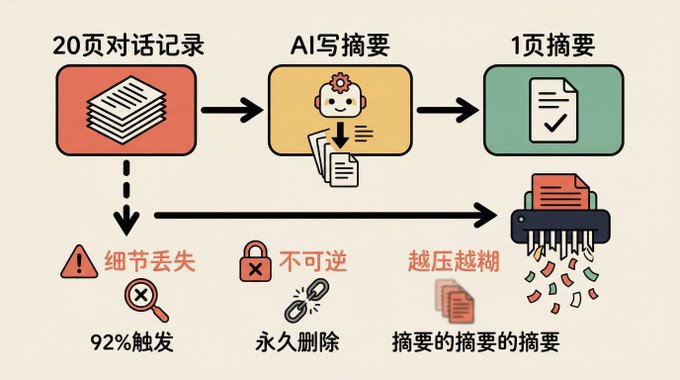
WHEN THE DIALOGUE IS FULL OF DESKTOP 92%, THE SYSTEM AUTOMATICALLY TRIGGERS COMPRESSION. KEEPS THE MOST RECENT THREE ROUNDS OF DIALOGUE, WITH ALL THE PREVIOUS CONTENTS PACKAGED FOR ANOTHER AI SUMMARY. FINISH THE SUMMARY AND POST IT BACK TO THE DESKTOP。
What about the conversation? Delete permanently. Can't find it back。
Just like your desk's almost full, you put 20 pages in front of you and asked your colleagues to write you a summary and throw that 20 pages into the shredder. The table is clear, but next time you want to remember how much that parameter was, I'm sorry, it's not back in the shredder。
The programme has three questions:
FIRST, THE SUMMARY WILL LOSE DETAILS. YOU TOLD AI THAT THE VARIABLE NAME WAS CHANGED, 20 ROUNDS LATER THE INFORMATION WAS COMPRESSED, AND AI USED THE OLD NAME BACK。
SECOND, IRREVERSIBLE. THE ORIGINAL DIALOGUE WAS PERMANENTLY LOST AND IT WAS IMPOSSIBLE TO FIND OUT WHY OPTION A HAD BEEN CHOSEN。
Thirdly, the pressure gets worse. If the compression triggers more than one time, it is a summary of the summary, and the information appears to be reproduced over and over again and is becoming less visible。
It works, but it's thrown every time it's compressed. The longer we talk, the more we lose。
Is there any way to compress, but not to throw things away
Programme II: Establishment of a layered archive
A strong team in the OpenClaw community made a second-generation program called Losles Cloud. The core commitment is intact, and the original message is always kept and none is deleted。
It's very clever. Do not delete the original and develop a thumbnail system。
Imagine Google Earth. You won't load every inch of the world's street view at the same time. You see: Earth's panorama, zoom in on the country, zoom in on the city, pull into the street。
This is what Losles Cloud did:
- Bottom (street view): Every original conversation, one word at a time, always in a local database
- Mid-level (city map): Summaries of relevant dialogues
- Top level (country map): global summary of the entire dialogue
Only the top-level summary is displayed on the desktop. Need details? Just turn it down. It's always there。
Much better than option one. At least don't throw things away。
But deep down, three questions came up:
FIRST, A NEW DIALOGUE WINDOW IS A MEMORY LOSS. THE ARCHIVE SERVES ONLY ONE DIALOGUE. YOU TURN OFF THE WINDOW AND OPEN A NEW, AI, ANOTHER WHITE PAPER. THE PITS THAT HAD BEEN STEPPED ON BY THE PREVIOUS PROJECT HAD YET TO BE STEPPED AGAIN。
Secondly, the desktop will be full. Although the originals were entered into the warehouse, the digest itself took up space. The longer the dialogue, the thicker the summary. Like more and more of your books, it's half a table。
THIRD, THE WAREHOUSE WAS TOO SLOW. TO FIND A SPECIFIC ORIGINAL RECORD, IT HAS TO BE CARRIED OUT FROM THE TOP LEVEL, THE PROCESS HAS TO CALL AI REPEATEDLY, AND YOU MAY HAVE TO WAIT TWO MINUTES TO GET THE RESULTS。
It did. But when you need it to remember, it turns too slow. And each time a new conversation takes place, it amounts to a new empty house。
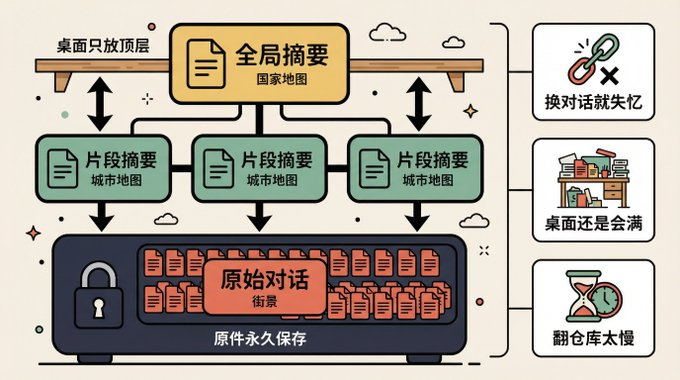
Here comes a more fundamental question:
Both options are thinking of the same thing, how to put more and more into a limited table. One is to throw away, one is to compress。
But is it possible that the thought itself is wrong
Option three: Don't pile it on the table. Just take it as needed
That's MemOS' idea. I've been working on my own, and I've seen it Agent Remember the most complete solution to this. It's a plugin for OpenClaw, open source free, 100% locally run, all data on your own computer, and zero upload。
MemOS 不再纠结怎么压缩,它问了一个完全不同的问题:为什么所有东西都得放桌上?
前两个方案像什么?像你要出差,硬往一个行李箱里塞所有的衣服。一种是扔掉几件(Legacy),一种是用真空压缩袋(Lossless Cloud)。行李箱还是那么大,早晚塞满。
MemOS 说:别背行李箱了。把衣服放在衣柜里,出门只带今天要穿的。
具体怎么做到的?
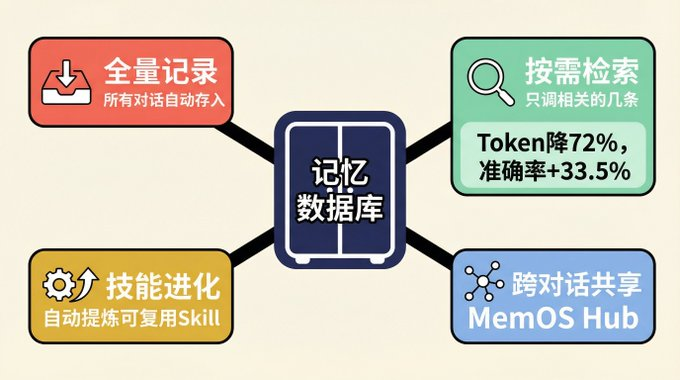
全量记录,但不往桌上放。 你跟 AI 的每一句对话、每一次操作,都自动存进一个独立的本地数据库。不挑不拣,全存。但这些记录不占桌面,它们安静地待在数据库里。如果你之前用的是 OpenClaw 自带的记忆功能,MemOS 支持一键迁移,之前积累的上下文不会白费。
按需检索,只调相关的。 AI 接到新任务时,不会把所有历史搬上桌面,而是像搜索引擎一样,根据当前任务去数据库里检索,只调出相关的几条。上周配过 Nginx?这次任务跟 Nginx 有关,那条记忆自动出现。无关的不占一寸桌面。
这个按需取的效果有多大?MemOS 团队跑了两组实测。
第一组是公开数据集 LOCOMO 的测试:token 消耗直接降了 72% 以上,同时准确率反而提升了 33.5%。省钱的同时还答得更准,因为上下文里塞的都是相关信息,噪音少了。
第二组是真实工程场景,跨多个会话完成复杂开发任务:对话轮次从平均 116 轮降到 54 轮,总 token 消耗从 220 万降到 112 万,砍掉了 49%。任务完成速度提升 2.15 倍。
以前桌面消耗跟聊了多久成正比,现在跟当前任务需要什么挂钩,基本恒定。
自动总结,浓缩经验。 每完成一个任务,系统自动生成结构化总结:做了什么、结论是什么、踩了什么坑。两小时的调试过程,浓缩成一张卡片。下次遇到类似任务,直接调出卡片就行。
技能自动进化。 这条最狠。系统会从重复出现的模式里提炼出可复用的 Skill。比如你让 AI 连续三次用同样的方式处理 CSV 文件,它自动总结出一条规则,下次直接照着来。而且这些 Skill 不是一成不变的,遇到更好的做法,它会自己升级。就像新员工从什么都要问变成有了自己的工作方法论,还在持续迭代。
跨对话、跨 Agent 共享。 前两个方案,换个对话窗口 AI 就失忆了。MemOS 不会。新对话开始时,系统自动检索相关记忆注入进来,上个项目的经验这个项目直接能用。如果你有多个 Agent,比如一个写代码,一个跑测试,它们共享同一个记忆库,一个人踩的坑全团队都能看到。MemOS 管这个叫 MemOS Hub,本质上就是一个团队知识中枢。
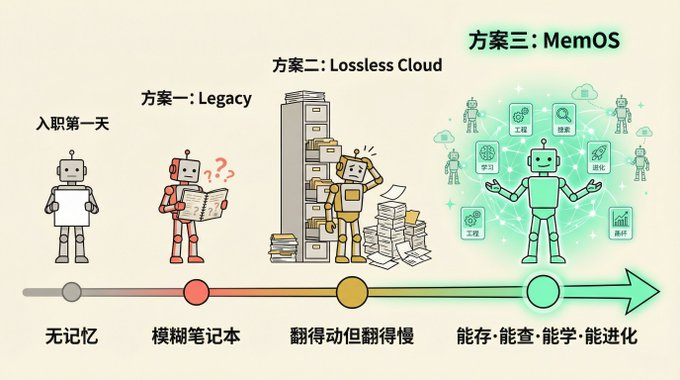
三种方案放在一起看
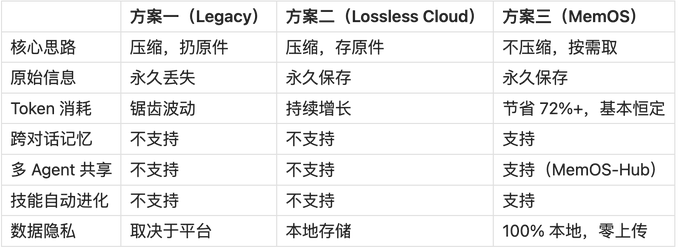
三个方案,对应了三种完全不同的记忆观:
方案一觉得记忆是负担,太多了,得压缩掉。
方案二觉得记忆是资产,不能丢,得保存好。
方案三觉得记忆是能力,不只是存着,还得会用,还得能进化。

想试试 MemOS?
MemOS 是 OpenClaw 的插件,开源免费,一行命令就能装。
Mac / Linux:
curl -fsSL https://cdn.memtensor.com.cn/memos-local-openclaw/install.sh | bashWindows(PowerShell):
powershell -c "irm https://cdn.memtensor.com.cn/memos-local-openclaw/install.ps1 | iex"插件主页和文档:
https://memos-claw.openmem.net/
装完配好大模型就能用,不需要额外的数据库和外部依赖。
记忆决定了 AI 能走多远
回到开头的承诺。
一个没有记忆的 AI,再聪明也只是永远停在入职第一天的实习生。每天来都很厉害,但昨天教的东西今天全忘了。
方案一给了它一本越写越模糊的摘要笔记。方案二给了它一个翻得动但翻得慢的档案馆。方案三给了它一套真正能用的知识管理系统,能存、能查、能学、能进化。
Agent 记忆这件事还很早期,但方向已经很明确了。未来的 AI 不只会更聪明,还会更记事。
一个记事的 AI,才是一个你愿意长期合作的 AI。